
![コンピュータ・システム プログラマの視点から [ 五島 正裕 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/2019/9784621302019.jpg?_ex=128x128 "コンピュータ・システム プログラマの視点から [ 五島 正裕 ]")
コンピュータ・システム プログラマの視点から [ 五島 正裕 ]
- 価格: 17600 円
- 楽天で詳細を見る
第2章 情報の表現と操作
現代のコンピュータは、2値の信号として表された情報を格納および処理します。これらの質素な2進数、またはビットは、デジタル革命の基礎を形成しています。馴染みのある10進数、または基数10の表現は、1,000年以上前から使用されており、インドで開発され、12世紀にアラブの数学者によって改良され、13世紀にはイタリアの数学者レオナルド・ピサーノ(約1170年から約1250年)によって西洋にもたらされました。フィボナッチとして知られています。10本の指を持つ人間にとって10進数表記を使用するのは自然ですが、情報を格納および処理する機械を構築する際には2進数がより効果的です。2値信号は簡単に表現、格納、および転送できます。たとえば、パンチカードの穴の有無、ワイヤ上の高いまたは低い電圧、または時計回りまたは反時計回りに向いた磁区などです。2値信号上での情報の格納および計算を行う電子回路は非常にシンプルで信頼性があり、製造業者はこれらの回路を単一のシリコンチップ上に数百万、あるいは数十億個も統合できます。
単独では、1ビットはあまり有用ではありません。ただし、ビットをグループ化し、さまざまな可能なビットパターンに意味を与える解釈を適用すると、任意の有限集合の要素を表すことができます。たとえば、2進数を使用して、ビットのグループを使用して非負の数をエンコードできます。標準の文字コードを使用することで、ドキュメント内の文字や記号をエンコードできます。この章では、これらのエンコーディングとともに、負の数を表すためのエンコーディングや実数を近似するためのエンコーディングについても説明します。
私たちは数字の3つの最も重要な表現を考えます。符号なしエンコーディングは、従来の2進数表記に基づいており、0以上の数を表します。2の補数エンコーディングは、符号付き整数、つまり正または負である可能性がある数を表す最も一般的な方法です。浮動小数点エンコーディングは、実数を表現するための科学的な表記の2進数版です。コンピュータは、これらの異なる表現に対して、整数や実数に対する対応する操作と同様に、加算や乗算などの算術演算を実装します。
コンピュータの表現は、数をエンコードするために限られたビット数を使用しており、したがって、一部の操作は結果が表現できる範囲を超えるとオーバーフローする可能性があります。これは予想外の結果を引き起こすことがあります。たとえば、今日のほとんどのコンピュータ(int型のデータに32ビットの表現を使用しているもの)では、次の式
200 * 300 * 400 * 500
を計算すると、結果は -884,901,888 になります。これは整数演算の特性とは逆に、一連の正の数の積を計算すると負の結果が得られることを示しています。
一方で、整数のコンピュータ演算は真の整数演算の多くの一般的な性質を満たします。たとえば、乗算は結合法則と交換法則を満たすため、次のいずれかのC式を計算すると、結果は-884,901,888になります:

コンピュータは期待される結果を生成しないかもしれませんが、少なくとも一貫性があります!
浮動小数点演算にはまったく異なる数学的な性質があります。一連の正の数の積は常に正であり、ただしオーバーフローが特別な値+∞を生成します。有限精度の表現のため、浮動小数点演算は結合法則を持っていません。例えば、Cの式 (3.14+1e20)-1e20 はほとんどのマシンで 0.0 に評価されますが、3.14+(1e20-1e20) は 3.14 に評価されます。整数演算と浮動小数点演算の異なる数学的性質は、それらの表現の有限性の扱いの違いから生じています。整数の表現は比較的小さな値の範囲を正確にエンコードできますが、浮動小数点の表現は広範囲の値をおおよそしかエンコードできません。
実際の数値表現を学ぶことで、表現できる値の範囲と異なる算術演算の性質を理解できます。この理解は、数値の全範囲で正確に動作し、異なる機械、オペレーティングシステム、コンパイラの組み合わせにわたって移植可能なプログラムを書く上で重要です。説明するように、コンピュータの算術の微妙な点のためにいくつかのセキュリティの脆弱性が生じています。以前の時代では、プログラムのバグはトリガーされたときにだけ人々に不便をかけるものでしたが、今ではハッカーが見つけたバグを悪用して他の人のシステムに不正アクセスを試みる軍団がいます。これにより、プログラマにはプログラムがどのように動作し、望ましくない方法で振る舞うようにできるかを理解する責任が高まっています。
コンピュータは、数値をエンコードするために複数の異なるバイナリ表現を使用しています。第3章で機械レベルのプログラミングに進む際に、これらの表現に精通している必要があります。この章ではこれらのエンコーディングを説明し、数値表現についての推論方法を示します。
私たちは数値のビットレベル表現を直接操作することによって算術演算を行ういくつかの方法を導出します。これらのテクニックを理解することは、コンパイラが算術式の評価のパフォーマンスを最適化しようとする際に生成される機械レベルのコードを理解する上で重要です。
この教材の取り扱いは、数学の基本的な原則の中核に基づいています。エンコーディングの基本的な定義から始め、表現可能な数値の範囲、ビットレベルの表現、および算術演算の性質などのプロパティを導出します。より抽象的な観点からこの教材を検討することは重要だと考えています。なぜなら、プログラマはコンピュータの算術がより馴染み深い整数および実数の算術と関連している方法を明確に理解している必要があるからです。
C++プログラミング言語は、同じ数値表現と操作を使用してCに基づいて構築されています。この章で述べられているCに関するすべてのことは、C++にも当てはまります。一方で、Java言語定義は、数値表現と操作の新しい標準セットを作成しました。Cの標準はさまざまな実装を許容するように設計されていますが、Javaの標準はデータのフォーマットとエンコーディングについて非常に具体的です。この章では、Javaがサポートする表現と操作をいくつかの場所で強調します。
この章では、コンピュータ上で数値や他の形式のデータがどのように表現され、コンピュータがこれらのデータに対して行う操作の基本的な特性を検討します。これには数学の言葉に入り、数式や方程式を書き、重要な特性の導出を示す必要があります。
この説明を理解するのに役立つように、プレゼンテーションを構造化して、まず数学的な表記で原則を述べます。その後、例と非形式的な議論でこの原則を説明します。原則の説明と例との間を行ったり来たりすることをお勧めします。より複雑な特性に対しては、数学的な証明のように構造化された導出も提供しています。これらの導出を最終的に理解しようとする努力が必要ですが、最初の読み取り時にはスキップしても構いません。
また、プレゼンテーションを進める中で練習問題に取り組むことをお勧めします。練習問題に取り組むことで、アクティブな学習が促進され、考えを実践に移すのに役立ちます。これらが背景となっていれば、導出の追跡がはるかに容易になるでしょう。また、この素材を理解するために必要な数学のスキルは、高校の代数をしっかり理解している人にとっては手の届く範囲にあります。
2.1 情報の記憶
メモリ内の個々のビットにアクセスする代わりに、ほとんどのコンピュータはメモリの最小のアドレス指定可能な単位として8ビット、またはバイトを使用しています。マシンレベルのプログラムでは、メモリを非常に大きなバイトの配列として表示し、これを仮想メモリと呼んでいます。メモリの各バイトは、そのアドレスとして知られる一意の番号で識別され、すべての可能なアドレスの集合は仮想アドレス空間として知られています。その名前が示すように、この仮想アドレス空間は単なる概念的なイメージであり、実際の実装(第9章で説明)では、動的ランダムアクセスメモリ(DRAM)、フラッシュメモリ、ディスクストレージ、特別なハードウェア、およびオペレーティングシステムソフトウェアの組み合わせを使用して、プログラムに見えるのは一枚のモノリシックな*1バイトの配列です。
次の章では、コンパイラとランタイムシステムがこのメモリスペースをより管理しやすい単位に分割して、プログラムの異なるオブジェクト、つまりプログラムデータ、命令、および制御情報を保存するかを説明します。さまざまなメカニズムがプログラムの異なる部分に対するストレージの割り当てと管理に使用されます。この管理はすべて仮想アドレススペース内で実行されます。たとえば、C言語のポインタの値は、整数、構造体、または他のプログラムオブジェクトを指しているかにかかわらず、あるブロックの最初のバイトの仮想アドレスです。Cコンパイラはまた、各ポインタに型情報を関連付けているため、その値の型に応じてポインタが指定する場所の値にアクセスするための異なる機械レベルのコードを生成できます。Cコンパイラはこの型情報を維持していますが、実際の機械レベルのプログラムはデータ型に関する情報を持っていません。それは単に各プログラムオブジェクトをバイトのブロックとして、プログラム自体をバイトのシーケンスとして扱います。
P40の余談に記述されている通り、Cプログラミング言語は最初、Unixオペレーティングシステム(同じくベル研究所で開発された)向けに、ベル研究所のデニス・リッチーによって開発されました。当時、ほとんどのシステムプログラム(オペレーティングシステムなど)は、さまざまなデータ型の低レベル表現にアクセスするために、主にアセンブリコードで書かれなければなりませんでした。例えば、当時の他の高級言語では、mallocライブラリ関数で提供されているようなメモリアロケータを書くことは実現不可能でした。
Cの元となるベル研究所版は、Brian KernighanとDennis Ritchieによる最初の版で文書化されました[60]。その後、Cはいくつかの標準化グループの努力を経て進化しました。元のベル研究所Cの大きな改訂は、1989年にアメリカ国家規格協会(ANSI)の傘下で作業していたグループによってANSI C標準につながりました。ANSI Cはベル研究所Cから大きく進化しており、特に関数が宣言される方法が異なります。ANSI Cについては、KernighanとRitchieの書籍の第2版[61]で説明されており、今でもCに関する最高の参照資料の一つと見なされています。
国際標準化機構(ISO)は、C言語の標準化の責任を引き継ぎ、1990年にANSI Cとほぼ同じバージョンを採用したため、「ISO C90」と呼ばれています。
この同じ組織は、1999年に言語を更新し、「ISO C99」となりました。このバージョンでは、新しいデータ型が導入され、英語にはない文字が必要なテキスト文字列をサポートしました。2011年に承認された最新の標準は「ISO C11」と呼ばれ、再びさらなるデータ型や機能が追加されました。これらの最近の追加のほとんどは後方互換性があり、以前の標準に従って書かれたプログラム(少なくともISO C90まで)は、新しい標準に従ってコンパイルされた場合に同じ動作をします。
GNU Compiler Collection(gcc)は、異なるコマンドラインオプションに基づいて、C言語のいくつかの異なるバージョンの規約に従ってプログラムをコンパイルできます(図2.1を参照)。たとえば、プログラムprog.cをISO C11に従ってコンパイルするには、次のコマンドラインを使用できます。
linux> gcc -std=c11 prog.c
オプション-ansiおよび-std=c89は同じ効果を持っています。コードはANSIまたはISO C90規格に従ってコンパイルされます(C90はその標準化の試みが1989年に始まったため、「C89」とも呼ばれます)。オプション-std=c99は、コンパイラにISO C99の規約に従うように指示します。
この本の執筆時点では、オプションが指定されていない場合、プログラムはISO C90に基づくCのバージョンに従ってコンパイルされますが、一部はC99、一部はC11、一部はC++、およびgcc固有の他の機能も含まれています。GNUプロジェクトは、ISO C11に他の機能を組み合わせたバージョンを開発しており、これはコマンドラインオプション-std=gnu11で指定できます(現時点では、この実装は未完成です)。これがデフォルトのバージョンになります。

ポインタはC言語の中核的な特徴です。これらは、データ構造や配列の要素への参照を可能にします。変数と同様に、ポインタには2つの側面があります:その値とその型です。値はあるオブジェクトの場所を示し、その型はその場所に格納されているオブジェクトの種類を示します(たとえば、整数または浮動小数点数など)。
ポインタを真に理解するには、その表現と機械レベルでの実装を調査する必要があります。これは第3章での主要な焦点となり、3.10.1節で詳細に説明されます。
2.1.1 十六進法表記
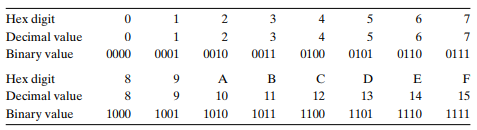
1 バイトは 8 ビットから成り立っています。2 進法表記では、その値は 00000000(2 進法)から 11111111(2 進法)までの範囲を持ちます。10 進法の整数として見ると、その値は 0 から 255 までの範囲を持ちます。どちらの表記もビットパターンを記述するのにはあまり適していません。2 進法表記は冗長すぎますし、10 進法表記ではビットパターンへの変換とビットパターンからの変換が煩雑です。その代わりに、ビットパターンを 16 進法(または単に「hex」と呼びます)の数字として書きます。16 進法は、‘0’ から ‘9’ までの数字と、‘A’ から ‘F’ までの文字を使用して、16 の可能な値を表します。図 2.2 は、16 進法の 16 の数字に関連する 10 進法と 2 進法の値を示しています。16 進法で書かれた場合、1 バイトの値は 00 から FF までの範囲を持ちます。
C言語では、0xまたは0Xで始まる数値定数は16進法と解釈されます。文字'A'から'F'は大文字でも小文字でも書くことができます。例えば、数字16進数のFA1D37Bは、0xFA1D37B、0xfa1d37b、または大文字と小文字を混在させて書くこともできます(例: 0xFa1D37b)。本書では16進法の値を表すためにCの表記法を使用します。
マシンレベルのプログラムでよく行われるタスクの一つは、ビットパターンの10進法、2進法、および16進法の表現を手動で変換することです。2進法と16進法の変換は比較的簡単で、1つの16進数の桁ずつ変換できます。図2.2に示されているようなチャートを参照して桁を変換できます。変換を頭で行うための簡単なテクニックとして、16進数の桁A、C、およびFの10進法の対応を覚えておくことがあります。16進法の値B、D、およびEは、最初の3つとの相対的な値を計算して10進法に変換できます。
例えば、数値が0x173A4Cと与えられた場合、各16進数の桁を拡張して2進数形式に変換できます。以下がその例です:
![]()
これにより、2進数の表現が000101110011101001001100となります。
逆に、2進数の1111001010110110110011を16進数に変換するには、まず4ビットごとにグループに分割します。ただし、合計ビット数が4の倍数でない場合は、左端のグループが4ビット未満となるようにし、効果的に先頭にゼロを埋め込みます。次に、各ビットグループを対応する16進数の数字に変換します:
![]()

値 x が 2 の冪であるとき、つまり x = 2^n(ここで n は非負整数)の場合、x を16進数形式で簡単に書くことができます。なぜなら、x のバイナリ表現は単に 1 の後に n 個のゼロが続くだけだからです。16進数の桁 0 は、4 つのバイナリゼロを表します。したがって、n を i + 4j の形で書くと(ここで 0 ≤ i ≤ 3)、x は、先頭に 1(i = 0)、2(i = 1)、4(i = 2)、または 8(i = 3)を付けた後に j 個の16進数の 0 が続く形で書くことができます。例として、x = 2,048 = 2^11 では、n = 11 = 3 + 4 . 2 となり、16進数表現は 0x800 です。


10進数と16進数の表現との変換は、一般的なケースを処理するために乗除算を使用する必要があります。10進数の数 x を16進数に変換するには、x を16で繰り返し割り、商 q と余り r を得ます(x = q . 16 + r)。そして、r を表す16進数の桁を最下位桁として使用し、q に対して同じプロセスを繰り返して残りの桁を生成します。例として、10進数の 314,156 を変換する場合を考えてみましょう。

この結果から、16進数の表現は0x4CB2Cと読み取ることができます。
逆に、16進数を10進数に変換するためには、各々の16進数の桁を16の適切な累乗で掛け算します。例えば、数字が0x7AFの場合、その10進数の等価値は、7 * 16^2 + 10 * 16^1 + 15 = 7 * 256 + 10 * 16 + 15 = 1,792 + 160 + 15 = 1,967 と計算できます。


10進数と16進数の間で大きな値を変換する際は、コンピュータや電卓に作業を任せるのが最善です。これを行うための多くのツールがあります。標準の検索エンジンを使用する一つの簡単な方法は、以下のようなクエリを入力することです。
「Convert 0xabcd to decimal」
または
「123 in hex」

*1: monolithic:一枚岩のような