
![コンピュータ・システム プログラマの視点から [ 五島 正裕 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/2019/9784621302019.jpg?_ex=128x128 "コンピュータ・システム プログラマの視点から [ 五島 正裕 ]")
コンピュータ・システム プログラマの視点から [ 五島 正裕 ]
- 価格: 17600 円
- 楽天で詳細を見る
2.1.2 データサイズ
すべてのコンピュータには、ポインタデータの名目のサイズを示すワードサイズがあります。仮想アドレスがそのようなワードでエンコードされるため、ワードサイズによって決まる最も重要なシステムパラメータは、仮想アドレス空間の最大サイズです。つまり、wビットのワードサイズを持つマシンの場合、仮想アドレスは0から2w - 1までの範囲になり、プログラムがアクセスできる最大のメモリは2wバイトです。
esthersoftware.hatenablog.com
近年、32ビットのワードサイズを持つマシンから、64ビットのワードサイズを持つマシンへの広範な移行が見られます。これは、まず大規模な科学やデータベースのアプリケーション向けに設計されたハイエンドマシンで始まり、次にデスクトップやラップトップのマシン、そして最近ではスマートフォンに搭載されたプロセッサでも見られます。32ビットのワードサイズでは仮想アドレス空間が4ギガバイト(4GB)、つまりバイトをわずかに超える範囲に制限されます。一方、64ビットのワードサイズにスケーリングすると、仮想アドレス空間が16エクサバイト、つまり約
バイトになります。
ほとんどの64ビットマシンは、32ビットマシン用にコンパイルされたプログラムも実行できます。これは、逆の互換性の一形態です。例えば、プログラムprog.cが次の指示でコンパイルされた場合、
linux> gcc -m32 prog.c
このプログラムは32ビットまたは64ビットのどちらのマシンでも正常に実行されます。一方で、次の指示でコンパイルされたプログラムは、
linux> gcc -m64 prog.c
64ビットのマシンでのみ実行されます。そのため、プログラムを「32ビットプログラム」または「64ビットプログラム」と呼びます。この区別は、プログラムがどのようにコンパイルされるかにあるため、実行されるマシンの種類ではなく、コンパイル方法に基づいています。
コンピュータとコンパイラは、整数や浮動小数点数などのデータをエンコードするためのさまざまな方法と、異なる長さをサポートすることで、複数のデータ形式をサポートしています。たとえば、多くのマシンは1バイトを操作する命令や、2、4、8バイトの量として表される整数を操作するための命令を持っています。また、4バイトおよび8バイトの量として表される浮動小数点数もサポートしています。
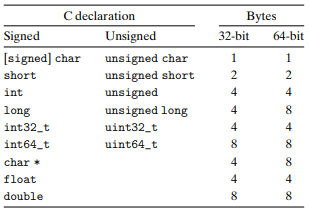
C言語は整数および浮動小数点データのために複数のデータ形式をサポートしています。図2.3には、異なるC言語のデータ型に通常割り当てられるバイト数が示されています(C標準で保証されるものと、実際のプログラムで一般的なものの関係については、セクション2.2で説明します)。いくつかのデータ型の正確なバイト数は、プログラムのコンパイル方法に依存します。通常の32ビットおよび64ビットプログラムのサイズを示しています。整数データは負の値、ゼロ、および正の値を表すことができる符号付きまたは非負の値のみを許可する符号なしになります。データ型charは1バイトを表します。charの名前は、テキスト文字列内の単一の文字を格納するために使用されていることから派生していますが、整数値を格納するためにも使用できます。short、int、およびlongというデータ型は、さまざまなサイズの範囲を提供することを意図しています。64ビットシステム向けにコンパイルされている場合でも、通常、intデータ型は通常4バイトです。longデータ型は、32ビットプログラムでは通常4バイト、64ビットプログラムでは通常8バイトです。
任意のデータ型 T に対して、宣言
T *p;
は、p が型 T のオブジェクトを指すポインタ変数であることを示します。例えば、
char *p;
は、char 型のオブジェクトを指すポインタの宣言です。
"典型的な" サイズや異なるコンパイラの設定に依存することを避けるために、ISO C99 では、データサイズがコンパイラやマシンの設定に関係なく一定の型が導入されました。その中には、int32_t と int64_t といったデータ型があり、それぞれ厳密に4バイトと8バイトです。固定サイズの整数型を使用することは、プログラマがデータの表現に対して緊密な制御を持つための最良の方法です。
ほとんどのデータ型は、unsigned で前置されるか、固定サイズのデータ型に対する特定の unsigned 宣言を使用しない限り、符号付きの値をエンコードします。例外はデータ型 char です。ほとんどのコンパイラとマシンはこれらを符号付きデータとして扱いますが、C 標準ではこれを保証していません。代わりに、角かっこで示されているように、プログラマは signed char 宣言を使用して1バイトの符号付き値を保証する必要があります。ただし、多くの文脈では、データ型 char が符号付きか符号なしかにプログラムの挙動が無関係であることがあります。
C言語では、キーワードの順序を変更したり、オプションのキーワードを含めたり省略したりする様々な方法が許容されています。例として、次の宣言はすべて同じ意味を持ちます。
- unsigned long
- unsigned long int
- long unsigned
- long unsigned int
私たちは常に 図 2.3 に示された形式を使用します。
図 2.3 によれば、ポインタ(たとえば、char * 型の変数)はプログラムのフルワードサイズを使用します。ほとんどのマシンはまた、2つの異なる浮動小数点形式をサポートしています。単精度は C で float と宣言され、4バイトを使用します。倍精度は C で double と宣言され、8バイトを使用します。
プログラマーは、プログラムが異なるマシンとコンパイラで移植可能であるよう努めるべきです。移植性の一部は、プログラムが異なるデータ型の正確なサイズに対して鈍感であるようにすることです。C の標準は、後で説明するように、異なるデータ型の数値範囲に下限を設定していますが(固定サイズの型を除く)、上限はありません。1980年頃から2010年頃まで、32ビットのマシンと32ビットのプログラムが主流であったため、多くのプログラムは図 2.3 で示されている32ビットプログラムの割り当てを前提として書かれています。64ビットのマシンへの移行に伴い、これらのプログラムを新しいマシンに移植する際の多くの非表示のワードサイズの依存関係が発生しました。たとえば、多くのプログラマは歴史的に、int 型として宣言されたオブジェクトをポインタを格納するために使用できると仮定していました。これはほとんどの32ビットプログラムには問題ありませんが、64ビットプログラムでは問題が発生します。